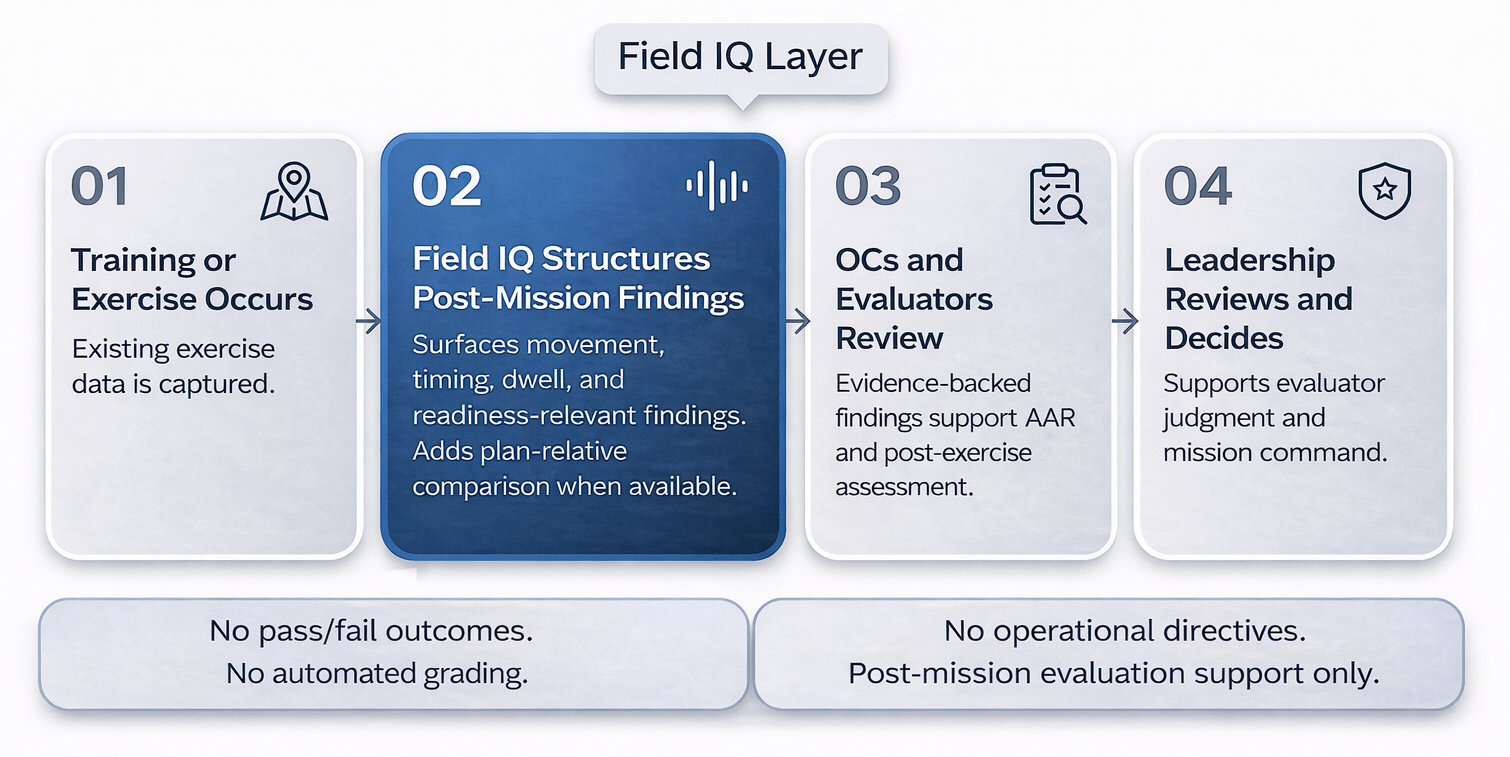
Field IQ supports teams responsible for explaining what happened after a mission, test, or exercise using data they already collect. These use cases align to real evaluation workflows where a narrow pilot can produce value quickly without replacing existing systems.
Improves evaluator consistency and reduces AAR subjectivity by producing standardized, evidence-backed review outputs across repeated training events.
One course block, 5–10 sessions, validate evaluator agreement and reduction in stitching time.
One test profile, one export format, 5–10 runs, one evaluator loop to validate time-to-first-finding.
Supports more consistent comparison across trials by producing repeatable post-mission findings under a controlled doctrine/configuration posture.
Sprint on 1–3 runs to validate outputs and define the pilot scope for larger experimentation.
Turns post-run review into repeatable, evidence-backed evaluation outputs that reduce reconstruction time and support more defensible assessment.
Start with 1 mission profile and 1 log export converted to CSV; run 3–10 trials; deliver repeatable evaluation artifacts.